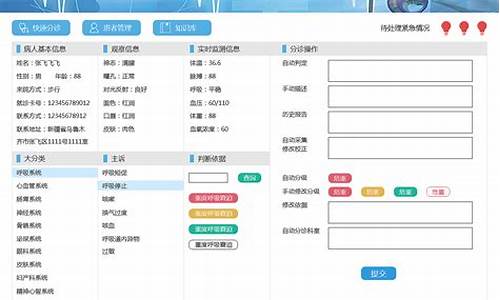
大数据电脑系统架构图,大数据电脑系统架构
1.hadoop大数据处理架构的核心技术是什么?
2.大数据平台有哪些架构
3.传统大数据存储的架构有哪些?各有什么特点?
4.大数据架构究竟用哪种框架更为合适
随着互联网的发展,越来越多的信息充斥在网络上,而大数据就是依靠对这些信息的收集、分类、归纳整理出我们所需要的信息,然后利用这些信息完成一些工作需要的一项能力技术。
今天,北京电脑培训主要就是来分析一下,大数据这项技术到底有那几个层次。
移动互联网时代,数据量呈现指数级增长,其中文本、音等非结构数据的占比已超过85%,未来将进一步增大。Hadoop架构的分布式文件系统、分布式数据库和分布式并行计算技术解决了海量多源异构数据在存储、管理和处理上的挑战。
从2006年4月第一个ApacheHadoop版本发布至今,Hadoop作为一项实现海量数据存储、管理和计算的开源技术,已迭代到了v2.7.2稳定版,其构成组件也由传统的三驾马车HDFS、MapReduce和HBase社区发展为由60多个相关组件组成的庞大生态,包括数据存储、执行引擎、编程和数据访问框架等。其生态系统从1.0版的三层架构演变为现在的四层架构:
底层——存储层
现在互联网数据量达到PB级,传统的存储方式已无法满足高效的IO性能和成本要求,Hadoop的分布式数据存储和管理技术解决了这一难题。HDFS现已成为大数据磁盘存储的事实标准,其上层正在涌现越来越多的文件格式封装(如Parquent)以适应BI类数据分析、机器学习类应用等更多的应用场景。未来HDFS会继续扩展对于新兴存储介质和服务器架构的支持。另一方面,区别于常用的Tachyon或Ignite,分布式内存文件系统新贵Arrow为列式内存存储的处理和交互提供了规范,得到了众多开发者和产业巨头的支持。
区别于传统的关系型数据库,HBase适合于非结构化数据存储。而Cloudera在2023年10月公布的分布式关系型数据库Kudu有望成为下一代分析平台的重要组成,它的出现将进一步把Hadoop市场向传统数据仓库市场靠拢。
中间层——管控层
管控层对Hadoop集群进行高效可靠的及数据管理。脱胎于MapReduce1.0的YARN已成为Hadoop2.0的通用管理平台。如何与容器技术深度融合,如何提高调度、细粒度管控和多租户支持的能力,是YARN需要进一步解决的问题。另一方面,Hortonworks的Ranger、Cloudera的Sentry和RecordService组件实现了对数据层面的安全管控。
hadoop大数据处理架构的核心技术是什么?
1、把你表中经常查询的和不常用的分开几个表,也就是横向切分
2、把不同类型的分成几个表,纵向切分
3、常用联接的建索引
4、服务器放几个硬盘,把数据、日志、索引分盘存放,这样可以提高IO吞吐率
5、用优化器,优化你的查询
6、考虑冗余,这样可以减少连接
7、可以考虑建立统计表,就是实时生成总计表,这样可以避免每次查询都统计一次
mrzxc 等说的好,考虑你的系统,注意负载平衡,查询优化,25 万并不大,可以建一个表,然后按mrzxc 的3 4 5 7 优化。 速度,影响它的因数太多了,且数据量越大越明显。
1、存储 将硬盘分成NTFS格式,NTFS比FAT32快,并看你的数据文件大小,1G以上你可以用多数据库文件,这样可以将存取负载分散到多个物理硬盘或磁盘阵列上。
2、tempdb tempdb也应该被单独的物理硬盘或磁盘阵列上,建议放在RAID 0上,这样它的性能最高,不要对它设置最大值让它自动增长
3、日志文件 日志文件也应该和数据文件分开在不同的理硬盘或磁盘阵列上,这样也可以提高硬盘I/O性能。
4、分区视图 就是将你的数据水平分割在集群服务器上,它适合大规模OLTP,SQL群集上,如果你数据库不是访问特别大不建议使用。
5、簇索引 你的表一定有个簇索引,在使用簇索引查询的时候,区块查询是最快的,如用between,应为他是物理连续的,你应该尽量减少对它的updaet,应为这可以使它物理不连续。
6、非簇索引 非簇索引与物理顺序无关,设计它时必须有高度的可选择性,可以提高查询速度,但对表update的时候这些非簇索引会影响速度,且占用空间大,如果你愿意用空间和修改时间换取速度可以考虑。
7、索引视图 如果在视图上建立索引,那视图的结果集就会被存储起来,对与特定的查询性能可以提高很多,但同样对update语句时它也会严重减低性能,一般用在数据相对稳定的数据仓库中。
8、维护索引 你在将索引建好后,定期维护是很重要的,用dbcc showcontig来观察页密度、扫描密度等等,及时用dbcc indexdefrag来整理表或视图的索引,在必要的时候用dbcc dbreindex来重建索引可以受到良好的效果。 不论你是用几个表1、2、3点都可以提高一定的性能,5、6、8点你是必须做的,至于4、7点看你的需求,我个人是不建议的。打了半个多小时想是在写论文,希望对你有帮助。
大数据平台有哪些架构
Hadoop核心架构,分为四个模块:
1、Hadoop通用:提供Hadoop模块所需要的Ja类库和工具。
2、Hadoop YARN:提供任务调度和集群管理功能。
3、Hadoop HDFS:分布式文件系统,提供高吞吐量的应用程序数据访问方式。
4、Hadoop MapReduce:大数据离线计算引擎,用于大规模数据集的并行处理。
特点:
Hadoop的高可靠性、高扩展性、高效性、高容错性,是Hadoop的优势所在,在十多年的发展历程当中,Hadoop依然被行业认可,占据着重要的市场地位。
Hadoop在大数据技术框架当中的地位重要,学大数据必学Hadoop,还要对Hadoop核心技术框架掌握扎实才行。
传统大数据存储的架构有哪些?各有什么特点?
01
传统大数据架构
之所以叫传统大数据架构,是因为其定位是为了解决传统BI的问题。
优点:
简单,易懂,对于BI系统来说,基本思想没有发生变化,变化的仅仅是技术选型,用大数据架构替换掉BI的组件。
缺点:
对于大数据来说,没有BI下完备的Cube架构,对业务支撑的灵活度不够,所以对于存在大量报表,或者复杂的钻取的场景,需要太多的手工定制化,同时该架构依旧以批处理为主,缺乏实时的支撑。
适用场景:
数据分析需求依旧以BI场景为主,但是因为数据量、性能等问题无法满足日常使用。
02
流式架构
在传统大数据架构的基础上,直接拔掉了批处理,数据全程以流的形式处理,所以在数据接入端没有了ETL,转而替换为数据通道。
优点:
没有臃肿的ETL过程,数据的实效性非常高。
缺点:
流式架构不存在批处理,对于数据的重播和历史统计无法很好的支撑。对于离线分析仅仅支撑窗口之内的分析。
适用场景:
预警,监控,对数据有有效期要求的情况。
03
Lambda架构
大多数架构基本都是Lambda架构或者基于其变种的架构。Lambda的数据通道分为两条分支:实时流和离线。
优点:
既有实时又有离线,对于数据分析场景涵盖的非常到位。
缺点:
离线层和实时流虽然面临的场景不相同,但是其内部处理的逻辑却是相同,因此有大量荣誉和重复的模块存在。
适用场景:
同时存在实时和离线需求的情况。
04
Ka架构
在Lambda 的基础上进行了优化,将实时和流部分进行了合并,将数据通道以消息队列进行替代。
优点:
解决了Lambda架构里面的冗余部分,以数据可重播的思想进行了设计,整个架构非常简洁。
缺点:
虽然Ka架构看起来简洁,但实施难度相对较高,尤其是对于数据重播部分。
适用场景:
和Lambda类似,改架构是针对Lambda的优化。
05
Unifield架构
以上的种种架构都围绕海量数据处理为主,Unifield架构则将机器学习和数据处理揉为一体,在流处理层新增了机器学习层。
优点:
提供了一套数据分析和机器学习结合的架构方案,解决了机器学习如何与数据平台进行结合的问题。
缺点:
实施复杂度更高,对于机器学习架构来说,从软件包到硬件部署都和数据分析平台有着非常大的差别,因此在实施过程中的难度系数更高。
适用场景:
有着大量数据需要分析,同时对机器学习方便又有着非常大的需求或者有规划。
大数据时代各种技术日新月异,想要保持竞争力就必须得不断地学习。写这些文章的目的是希望能帮到一些人了解学习大数据相关知识 。加米谷大数据,大数据人才培养机构,喜欢的同学可关注下,每天花一点时间学习,长期积累总是会有收获的。
大数据架构究竟用哪种框架更为合适
数据时代,移动互联、社交网络、数据分析、云服务等应用的迅速普及,对数据中心提出革命性的需求,存储基础架构已经成为IT核心之一。、军队军工、科研院所、航空航天、大型商业连锁、医疗、金融、新媒体、广电等各个领域新兴应用层出不穷。数据的价值日益凸显,数据已经成为不可或缺的资产。作为数据载体和驱动力量,存储系统成为大数据基础架构中最为关键的核心。
传统的数据中心无论是在性能、效率,还是在投资收益、安全,已经远远不能满足新兴应用的需求,数据中心业务急需新型大数据处理中心来支撑。除了传统的高可靠、高冗余、绿色节能之外,新型的大数据中心还需具备虚拟化、模块化、弹性扩展、自动化等一系列特征,才能满足具备大数据特征的应用需求。这些史无前例的需求,让存储系统的架构和功能都发生了前所未有的变化。
基于大数据应用需求,“应用定义存储”概念被提出。存储系统作为数据中心最核心的数据基础,不再仅是传统分散的、单一的底层设备。除了要具备高性能、高安全、高可靠等特征之外,还要有虚拟化、并行分布、自动分层、弹性扩展、异构整合、全局缓存加速等多方面的特点,才能满足具备大数据特征的业务应用需求。
尤其在云安防概念被热炒的时代,随着技术的普及,720P、1080P随处可见,智能和的双向需求、动辄500W、800W甚至上千万更高分辨率的摄像机面市,大数据对存储设备的容量、读写性能、可靠性、扩展性等都提出了更高的要求,需要充分考虑功能集成度、数据安全性、数据稳定性,系统可扩展性、性能及成本各方面因素。
目前市场上的存储架构如下:
(1)基于嵌入式架构的存储系统
节点NVR架构主要面向小型监控系统,前端数量一般在几十路以内。系统建设中没有大型的存储监控中心机房,存储容量相对较小,用户体验度、系统功能集成度要求较高。在市场应用层面,超市、店铺、小型企业、政法行业中基本管理单元等应用较为广泛。
(2)基于X86架构的存储系统
平台SAN架构主要面向中大型监控系统,前端路数成百上千甚至上万。一般多用IPSAN或FCSAN搭建存储系统。作为监控平台的重要组成部分,前端监控数据通过录像存储管理模块存储到SAN中。
此种架构接入前端路数相对节点NVR有了较高提升,具备快捷便利的可扩展性,技术成熟。对于IPSAN而言,虽然在ISCSI环节数据并发读写传输速率有所消耗,但其凭借扩展性良好、硬件平台通用、海量数据可充分共享等优点,仍然得到很多客户的青睐。FCSAN在行业用户、封闭存储系统中应用较多,比如县级或地级市监控项目,大数据量的并发读写对千兆网络交换提出了较大的挑战,但应用FCSAN构建相对独立的存储子系统,可以有效解决上述问题。
面对监控系统大文件、随机读写的特点,平台SAN架构系统不同存储单元之间的数据共享冗余方面还有待提高;从高性能服务器转发数据到存储空间的策略,从系统架构而言也增加了隐患故障点、ISCSI带宽瓶颈导致无法充分利用硬件数据并发性能、接入前端数据较少。上述问题催生了平台NVR架构解决方案。
该方案在系统架构上省去了存储服务器,消除了上文提到的性能瓶颈和单点故障隐患。大幅度提高存储系统的写入和检索速度;同时也彻底消除了传统文件系统由于供电和网络的不稳定带来的文件系统损坏等问题。
平台NVR中存储的数据可同时供多个客户端随时查询,点播,当用户需要查看多个已保存的监控数据时,可通过授权的监控客户端直接查询并点播相应位置的监控数据进行历史图像的查看。由于数据管理服务器具有监控系统所有监控点的录像文件的索引,因此通过平台CMS授权,监控客户端可以查询并点播整个监控系统上所有监控点的数据,这个过程对用户而言也是透明的。
(3)基于云技术的存储方案
当前,安防行业可谓“云”山“物”罩。随着监控的化和网络化,存储和管理的数据量已有海量之势,云存储技术是突破IP监控存储瓶颈的重要手段。云存储作为一种服务,在未来安防监控行业有着可观的应用前景。
与传统存储设备不同,云存储不仅是一个硬件,而是一个由网络设备、存储设备、服务器、软件、接入网络、用户访问接口以及客户端程序等多个部分构成的复杂系统。该系统以存储设备为核心,通过应用层软件对外提供数据存储和业务服务。
一般分为存储层、基础管理层、应用接口层以及访问层。存储层是云存储系统的基础,由存储设备(满足FC协议、iSCSI协议、NAS协议等)构成。基础管理层是云存储系统的核心,其担负着存储设备间协同工作,数据加密,分发以及容灾备份等工作。应用接口层是系统中根据用户需求来开发的部分,根据不同的业务类型,可以开发出不同的应用服务接口。访问层指授权用户通过应用接口来登录、享受云服务。其主要优势在于:硬件冗余、节能环保、系统升级不会影响存储服务、海量并行扩容、强大的负载均衡功能、统一管理、统一向外提供服务,管理效率高,云存储系统从系统架构、文件结构、高速缓存等方面入手,针对监控应用进行了优化设计。数据传输可用流方式,底层用突破传统文件系统限制的流媒体数据结构,大幅提高了系统性能。
监控存储是一种大码流多并发写为主的存储应用,对性能、并发性和稳定性等方面有很高的要求。该存储解决方案用独特的大缓存顺序化算法,把多路随机并发访问变为顺序访问,解决了硬盘磁头因频繁寻道而导致的性能迅速下降和硬盘寿命缩短的问题。
针对系统中会产生PB级海量监控数据,存储设备的数量达数十台上百台,因此管理方式的科学高效显得十分重要。云存储可提供基于集群管理技术的多设备集中管理工具,具有设备集中监控、集群管理、系统软硬件运行状态的监控、主动报警,图像化系统检测等功能。在海量存储检索应用中,检索性能尤为重要。传统文件系统中,文件检索用的是“目录-》子目录-》文件-》定位”的检索步骤,在海量数据的监控,目录和文件数量十分可观,这种检索模式的效率就会大打折扣。用序号文件定位可以有效解决该问题。
云存储可以提供非常高的的系统冗余和安全性。当在线存储系统出现故障后,热备机可以立即接替服务,当故障恢复时,服务和数据回迁;若故障机数据需要调用,可以将故障机的磁盘插入到冷备机中,实现所有数据的立即可用。
对于监控系统,随着监控前端的增加和存储时间的延长,扩展能力十分重要。市场中已有友商可提供单纯针对容量的扩展柜扩展模式和性能容量同步线性扩展的堆叠扩展模式。
云存储系统除上述优点之外,在平台对接整合、业务流程梳理、数据智能分析深度挖掘及成本方面都将面临挑战。承建大型系统、构建云存储的商业模式也亟待创新。受限于宽带网络、web2.0技术、应用存储技术、文件系统、P2P、数据压缩、CDN技术、虚拟化技术等的发展,未来云存储还有很长的路要走。
一般而言,架构有两个要素:它是一个软件系统从整体到部分的最高层次的划分
一个系统通常是由元件组成的,而这些元件如何形成、相互之间如何发生作用,则是关于这个系统本身结构的重要信息
详细地说,就是要包括架构元件()、联结器(Connector)、任务流(Task-flow)
所谓架构元素,也就是组成系统的核心"砖瓦",而联结器则描述这些元件之间通讯的路径、通讯的机制、通讯的预期结果,任务流则描述系统如何使用这些元件和联结器完成某一项需求
建造一个系统所作出的最高层次的、以后难以更改的,商业的和技术的决定
在建造一个系统之前会有很多的重要决定需要事先作出,而一旦系统开始进行详细设计甚至建造,这些决定就很难更改甚至无法更改
显然,这样的决定必定是有关系统设计成败的最重要决定,必须经过非常慎重的研究和考察
计算机软件的历史开始于五十年代,历史非常短暂,而相比之下建筑工程则从石器时代就开始了,人类在几千年的建筑设计实践中积累了大量的经验和教训
建筑设计基本上包含两点,一是建筑风格,二是建筑模式
独特的建筑风格和恰当选择的建筑模式,可以使一个独一无二
正如同软件本身有其要达到的目标一样,架构设计要达到的目标是什么呢?一般而言,软件架构设计要达到如下的目标:·可靠性(Reliable)
软件系统对于用户的商业经营和管理来说极为重要,因此软件系统必须非常可靠
安全性(Secure)
软件系统所承担的交易的商业价值极高,系统的安全性非常重要
可扩展性(Scalable)
软件必须能够在用户的使用率、用户的数目增加很快的情况下,保持合理的性能
只有这样,才能适应用户的市场扩展得可能性
可定制化()
同样的一套软件,可以根据客户群的不同和市场需求的变化进行调整
可扩展性(Extensible)
在新技术出现的时候,一个软件系统应当允许导入新技术,从而对现有系统进行功能和性能的扩展
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。