电脑系统nms-电脑系统有哪几种
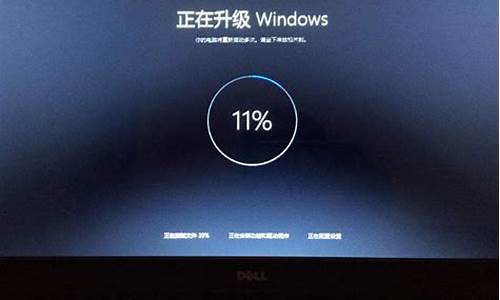
1.电脑一开机就显示下面这些东西 A7309NMS V9.3 010909 AMD Athlon(tm) 64×2 Dual c
2.电脑开机出现a7309nms V9.2 090508
3.什么是P2P是下载器
4.网管需要买些什么
电脑一开机就显示下面这些东西 A7309NMS V9.3 010909 AMD Athlon(tm) 64×2 Dual c

Press F1 to Run SETUP
按F1进入设置
Press F2 load default values and continue
按F2载入默认值并继续
提示应该在这上面的几行中,可以拍照发上来。
电脑开机出现a7309nms V9.2 090508
按住开机键不动,一会就关机。再开机重启按住F8键不动,出现开机菜单时,选择最后一次正确配置,回车试。不行的话,你再重启,出现菜单选安全模式,进入杀毒、360卫士扫描,处理完,重启试试。如都进不去只能重装系统。
什么是P2P是下载器
P2P普及系列之一
拓扑结构是指分布式系统中各个计算单元之间的物理或逻辑的互联关系,结点之间的拓扑结构一直是确定系统类型的重要依据。目前互联网络中广泛使用集中式、层次式等拓扑结构,Interne本身是世界上最大的非集中式的互联网络,但是九十年代所建立的一些网络应用系统却是完全的集中式的系统、很多Web应用都是运行在集中式的服务器系统上。集中式拓扑结构系统目前面临着过量存储负载、Dos攻击等一些难以解决的问题。
P2P系统一般要构造一个非集中式的拓扑结构,在构造过程中需要解决系统中所包含的大量结点如何命名、组织以及确定结点的加入/离开方式、出错恢复等问题。
根据拓扑结构的关系可以将P2P研究分为4种形式:中心化拓扑(Centralized Topology);全分布式非结构化拓扑(Decentralized Unstructured Topology);全分布式结构化拓扑(Decentralized Structured Topology,也称作DHT网络)和半分布式拓扑(Partially Decentralized Topology)。
其中,中心化拓扑最大的优点是维护简单发现效率高。由于资源的发现依赖中心化的目录系统,发现算法灵活高效并能够实现复杂查询。最大的问题与传统客户机/服务器结构类似,容易造成单点故障,访问的“热点”现象和法律等相关问题,这是第一代P2P网络采用的结构模式,经典案例就是著名的MP3共享软件Napster。
Napster是最早出现的P2P系统之一,并在短期内迅速成长起来。Napster实质上并非是纯粹的P2P系统,它通过一个中央服务器保存所有Napster用户上传的音乐文件索引和存放位置的信息。当某个用户需要某个音乐文件时,首先连接到Napster服务器,在服务器进行检索,并由服务器返回存有该文件的用户信息;再由请求者直接连到文件的所有者传输文件。
Napster首先实现了文件查询与文件传输的分离,有效地节省了中央服务器的带宽消耗,减少了系统的文件传输延时。这种方式最大的隐患在中央服务器上,如果该服务器失效,整个系统都会瘫痪。当用户数量增加到105或者更高时,Napster的系统性能会大大下降。另一个问题在于安全性上,Napster并没有提供有效的安全机制。
在Napster模型中,一群高性能的中央服务器保存着网络中所有活动对等计算机共享资源的目录信息。当需要查询某个文件时,对等机会向一台中央服务器发出文件查询请求。中央服务器进行相应的检索和查询后,会返回符合查询要求的对等机地址信息列表。查询发起对等机接收到应答后,会根据网络流量和延迟等信息进行选择,和合适的对等机建立连接,并开始文件传输。
这种对等网络模型存在很多问题,主要表现为:
(1)中央服务器的瘫痪容易导致整个网络的崩馈,可靠性和安全性较低。
(2)随着网络规模的扩大,对中央索引服务器进行维护和更新的费用将急剧增加,所需成本过高。
(3)中央服务器的存在引起共享资源在版权问题上的纠纷,并因此被攻击为非纯粹意义上的P2P网络模型。对小型网络而言,集中目录式模型在管理和控制方面占一定优势。但鉴于其存在的种种缺陷,该模型并不适合大型网络应用。
P2P普及系列之二
Pastry是微软研究院提出的可扩展的分布式对象定位和路由协议,可用于构建大规模的P2P系统。在Pastry中,每个结点分配一个128位的结点标识符号(nodeID) ,所有的结点标识符形成了一个环形的nodeID空间,范围从0到2128 - 1 ,结点加入系统时通过散列结点IP地址在128位nodeID空间中随机分配。
在MIT,开展了多个与P2P相关的研究项目:Chord,GRID和RON。Chord项目的目标是提供一个适合于P2P环境的分布式资源发现服务,它通过使用DHT技术使得发现指定对象只需要维护O(logN)长度的路由表。
在DHT技术中,网络结点按照一定的方式分配一个唯一结点标识符(Node ID) ,资源对象通过散列运算产生一个唯一的资源标识符(Object ID) ,且该资源将存储在结点ID与之相等或者相近的结点上。需要查找该资源时,采用同样的方法可定位到存储该资源的结点。因此,Chord的主要贡献是提出了一个分布式查找协议,该协议可将指定的关键字(Key) 映射到对应的结点(Node) 。从算法来看,Chord是相容散列算法的变体。MIT GRID和RON项目则提出了在分布式广域网中实施查找资源的系统框架。
T&T ACIRI中心的CAN(Content Addressable Networks) 项目独特之处在于采用多维的标识符空间来实现分布式散列算法。CAN将所有结点映射到一个n维的笛卡尔空间中,并为每个结点尽可能均匀的分配一块区域。CAN采用的散列函数通过对(key, value) 对中的key进行散列运算,得到笛卡尔空间中的一个点,并将(key, value) 对存储在拥有该点所在区域的结点内。CAN采用的路由算法相当直接和简单,知道目标点的坐标后,就将请求传给当前结点四邻中坐标最接近目标点的结点。CAN是一个具有良好可扩展性的系统,给定N个结点,系统维数为d,则路由路径长度为O(n1/d) ,每结点维护的路由表信息和网络规模无关为O(d) 。
DHT类结构最大的问题是DHT的维护机制较为复杂,尤其是结点频繁加入退出造成的网络波动(Churn)会极大增加DHT的维护代价。DHT所面临的另外一个问题是DHT仅支持精确关键词匹配查询,无法支持内容/语义等复杂查询。
半分布式结构(有的文献称作 Hybrid Structure)吸取了中心化结构和全分布式非结构化拓扑的优点,选择性能较高(处理、存储、带宽等方面性能)的结点作为超级点(英文文献中多称作:SuperNodes, Hubs),在各个超级点上存储了系统中其他部分结点的信息,发现算法仅在超级点之间转发,超级点再将查询请求转发给适当的叶子结点。半分布式结构也是一个层次式结构,超级点之间构成一个高速转发层,超级点和所负责的普通结点构成若干层次。最典型的案例就是KaZaa。
KaZaa是现在全世界流行的几款p2p软件之一。根据CA公司统计,全球KaZaa的下载量超过2.5亿次。使用KaZaa软件进行文件传输消耗了互联网40%的带宽。之所以它如此的成功,是因为它结合了Napster和Gnutella共同的优点。从结构 上来说,它使用了Gnutella的全分布式的结构,这样可以是系统更好的扩展,因为它无需中央索引服务器存储文件名,它是自动的把性能好的机器成为SuperNode,它存储着离它最近的叶子节点的文件信息,这些SuperNode,再连通起来形成一个Overlay Network. 由于SuperNode的索引功能,使搜索效率大大提高。
P2P普及系列之三
全分布非结构化网络在重叠网络(overlay)采用了随机图的组织方式,结点度数服从"Power-law"[a][b]规律,从而能够较快发现目的结点,面对网络的动态变化体现了较好的容错能力,因此具有较好的可用性。同时可以支持复杂查询,如带有规则表达式的多关键词查询,模糊查询等,最典型的案例是Gnutella。
Gnutella是一个P2P文件共享系统,它和Napster最大的区别在于Gnutella是纯粹的P2P系统,没有索引服务器,它采用了基于完全随机图的洪泛(Flooding)发现和随机转发(Random Walker)机制。为了控制搜索消息的传输,通过TTL (Time To Live)的减值来实现。具体协议参照〔Gnutella协议中文版〕
在Gnutella分布式对等网络模型N中,每一个联网计算机在功能上都是对等的,既是客户机同时又是服务器,所以被称为对等机(Servent,Server+Client的组合)。
随着联网节点的不断增多,网络规模不断扩大,通过这种洪泛方式定位对等点的方法将造成网络流量急剧增加,从而导致网络中部分低带宽节点因网络资源过载而失效。所以在初期的Gnutella网络中,存在比较严重的分区,断链现象。也就是说,一个查询访问只能在网络的很小一部分进行,因此网络的可扩展性不好。所以,解决Gnutella网络的可扩展性对该网络的进一步发展至关重要。
由于没有确定拓扑结构的支持,非结构化网络无法保证资源发现的效率。即使需要查找的目的结点存在发现也有可能失败。由于采用TTL(Time-to-Live)、洪泛(Flooding)、随机漫步或有选择转发算法,因此直径不可控,可扩展性较差。
因此发现的准确性和可扩展性是非结构化网络面临的两个重要问题。目前对此类结构的研究主要集中于改进发现算法和复制策略以提高发现的准确率和性能。
全分布非结构化网络在重叠网络(overlay)采用了随机图的组织方式,结点度数服从"Power-law"[a][b]规律,从而能够较快发现目的结点,面对网络的动态变化体现了较好的容错能力,因此具有较好的可用性。同时可以支持复杂查询,如带有规则表达式的多关键词查询,模糊查询等,最典型的案例是Gnutella。
Gnutella是一个P2P文件共享系统,它和Napster最大的区别在于Gnutella是纯粹的P2P系统,没有索引服务器,它采用了基于完全随机图的洪泛(Flooding)发现和随机转发(Random Walker)机制。为了控制搜索消息的传输,通过TTL (Time To Live)的减值来实现。具体协议参照〔Gnutella协议中文版〕
在Gnutella分布式对等网络模型N中,每一个联网计算机在功能上都是对等的,既是客户机同时又是服务器,所以被称为对等机(Servent,Server+Client的组合)。
随着联网节点的不断增多,网络规模不断扩大,通过这种洪泛方式定位对等点的方法将造成网络流量急剧增加,从而导致网络中部分低带宽节点因网络资源过载而失效。所以在初期的Gnutella网络中,存在比较严重的分区,断链现象。也就是说,一个查询访问只能在网络的很小一部分进行,因此网络的可扩展性不好。所以,解决Gnutella网络的可扩展性对该网络的进一步发展至关重要。
由于没有确定拓扑结构的支持,非结构化网络无法保证资源发现的效率。即使需要查找的目的结点存在发现也有可能失败。由于采用TTL(Time-to-Live)、洪泛(Flooding)、随机漫步或有选择转发算法,因此直径不可控,可扩展性较差。
因此发现的准确性和可扩展性是非结构化网络面临的两个重要问题。目前对此类结构的研究主要集中于改进发现算法和复制策略以提高发现的准确率和性能。
P2P普及系列之四
半分布式结构的优点是性能、可扩展性较好,较容易管理,但对超级点依赖性大,易于受到攻击,容错性也受到影响。下表比较了4种结构的综合性能,比较结果如表1-1所示。
比较标准/拓扑结构 中心化拓扑 全分布式非结构化拓扑 全分布式结构化拓扑 半分布式拓扑
可扩展性 差 差 好 中
可靠性 差 好 好 中
可维护性 最好 最好 好 中
发现算法效率 最高 中 高 中
复杂查询 支持 支持 不支持 支持
表1:4种结构的性能比较
P2P普及系列之五
国外开展P2P研究的学术团体主要包括P2P工作组(P2PWG) 、全球网格论坛(Global Grid Forum ,GGF) 。P2P工作组成立的主要目的是希望加速P2P计算基础设施的建立和相应的标准化工作。P2PWG成立之后,对P2P计算中的术语进行了统一,也形成相关的草案,但是在标准化工作方面工作进展缓慢。目前P2PWG已经和GGF合并,由该论坛管理P2P计算相关的工作。GGF负责网格计算和P2P计算等相关的标准化工作。
从国外公司对P2P计算的支持力度来看,Microsoft公司、Sun公司和Intel公司投入较大。Microsoft公司成立了Pastry项目组,主要负责P2P计算技术的研究和开发工作。目前Microsoft公司已经发布了基于Pastry的软件包SimPastry/ VisPastry。Rice大学也在Pastry的基础之上发布了FreePastry软件包。
在2000年8月,Intel公司宣布成立P2P工作组,正式开展P2P的研究。工作组成立以后,积极与应用开发商合作,开发P2P应用平台。2002年Intel发布了. Net基础架构之上的Accelerator Kit (P2P加速工具包) 和P2P安全API软件包,从而使得微软. NET开发人员能够迅速地建立P2P安全Web应用程序。
Sun公司以Java技术为背景,开展了JXTA项目。JXTA是基于Java的开源P2P平台,任何个人和组织均可以加入该项目。因此,该项目不仅吸引了大批P2P研究人员和开发人员,而且已经发布了基于JXTA的即时聊天软件包。JXTA定义了一组核心业务:认证、资源发现和管理。在安全方面,JXTA加入了加密软件包,允许使用该加密包进行数据加密,从而保证消息的隐私、可认证性和完整性。在JXTA核心之上,还定义了包括内容管理、信息搜索以及服务管理在内的各种其它可选JXTA服务。在核心服务和可选服务基础上,用户可以开发各种JXTA平台上的P2P应用。
P2P实际的应用主要体现在以下几个方面:
P2P分布式存储
P2P分布式存储系统是一个用于对等网络的数据存储系统,它可以提供高效率的、鲁棒的和负载平衡的文件存取功能。这些研究包括:OceanStore,Farsite等。其中,基于超级点结构的半分布式P2P应用如Kazza、Edonkey、Morpheus、Bittorrent等也是属于分布式存储的范畴,并且用户数量急剧增加。
计算能力的共享
加入对等网络的结点除了可以共享存储能力之外,还可以共享CPU处理能力。目前已经有了一些基于对等网络的计算能力共享系统。比如SETI@home。目前SETI@home采用的仍然是类似于Napster的集中式目录策略。Xenoservers向真正的对等应用又迈进了一步。这种计算能力共享系统可以用于进行基因数据库检索和密码破解等需要大规模计算能力的应用。
P2P应用层组播
应用层组播,就是在应用层实现组播功能而不需要网络层的支持。这样就可以避免出现由于网络层迟迟不能部署对组播的支持而使组播应用难以进行的情况。应用层组播需要在参加的应用结点之间实现一个可扩展的,支持容错能力的重叠网络,而基于DHT的发现机制正好为应用层组播的实现提供了良好的基础平台。
Internet间接访问基础结构(Internet Indirection Infrastructure)。
为了使Internet更好地支持组播、单播和移动等特性,Internet间接访问基础结构提出了基于汇聚点的通信抽象。在这一结构中,并不把分组直接发向目的结点,而是给每个分组分配一个标识符,而目的结点则根据标识符接收相应的分组。标识符实际上表示的是信息的汇聚点。目的结点把自己想接收的分组的标识符预先通过一个触发器告诉汇聚点,当汇聚点收到分组时,将会根据触发器把分组转发该相应的目的结点。Internet间接访问基础结构实际上在Internet上构成了一个重叠网络,它需要对等网络的路由系统对它提供相应的支持。
P2P技术从出现到各个领域的应用展开,仅用了几年的时间。从而证明了P2P技术具有非常广阔的应用前景。
P2P普及系列之六
随着P2P应用的蓬勃发展,作为P2P应用中核心问题的发现技术除了遵循技术本身的逻辑以外,也受到某些技术的发展趋势、需求趋势的深刻影响。
如上所述,DHT发现技术完全建立在确定性拓扑结构的基础上,从而表现出对网络中路由的指导性和网络中结点与数据管理的较强控制力。但是,对确定性结构的认识又限制了发现算法效率的提升。研究分析了目前基于DHT的发现算法,发现衡量发现算法的两个重要参数度数(表示邻居关系数、路由表的容量)和链路长度(发现算法的平均路径长度)之间存在渐进曲线的关系。
研究者采用图论中度数(Degree)和直径(Diameter)两个参数研究DHT发现算法,发现这些DHT发现算法在度数和直径之间存在渐进曲线关系,如下图所示。在N个结点网络中,图中直观显示出当度数为N时,发现算法的直径为O(1);当每个结点仅维护一个邻居时,发现算法的直径为O(N)。这是度数和直径关系的2种极端情况。同时,研究以图论的理论分析了O(d)的度和O(d)的直径的算法是不可能的。
从渐进曲线关系可以看出,如果想获得更短的路径长度,必然导致度数的增加;而网络实际连接状态的变化造成大度数邻居关系的维护复杂程度增加。另外,研究者证明O(logN)甚至O(logN/loglogN)的平均路径长度也不能满足状态变化剧烈的网络应用的需求。新的发现算法受到这种折衷关系制约的根本原因在于DHT对网络拓扑结构的确定性认识。
非结构化P2P系统中发现技术一直采用洪泛转发的方式,与DHT的启发式发现算法相比,可靠性差,对网络资源的消耗较大。最新的研究从提高发现算法的可靠性和寻找随机图中的最短路径两个方面展开。也就是对重叠网络的重新认识。其中,small world特征和幂规律证明实际网络的拓扑结构既不是非结构化系统所认识的一个完全随机图,也不是DHT发现算法采用的确定性拓扑结构。
实际网络体现的幂规律分布的含义可以简单解释为在网络中有少数结点有较高的“度”,多数结点的“度”较低。度较高的结点同其他结点的联系比较多,通过它找到待查信息的概率较高。
Small-world[a][b]模型的特性:网络拓扑具有高聚集度和短链的特性。在符合small world特性的网络模型中,可以根据结点的聚集度将结点划分为若干簇(Cluster),在每个簇中至少存在一个度最高的结点为中心结点。大量研究证明了以Gnutella为代表的P2P网络符合small world特征,也就是网络中存在大量高连通结点,部分结点之间存在“短链”现象。
因此,P2P发现算法中如何缩短路径长度的问题变成了如何找到这些“短链”的问题。尤其是在DHT发现算法中,如何产生和找到“短链”是发现算法设计的一个新的思路。small world特征的引入会对P2P发现算法产生重大影响。
P2P普及系列之七
有DHT算法由于采用分布式散列函数,所以只适合于准确的查找,如果要支持目前Web上搜索引擎具有的多关键字查找的功能,还要引入新的方法。主要的原因在于DHT的工作方式。
基于DHT的P2P系统采用相容散列函数根据精确关键词进行对象的定位与发现。散列函数总是试图保证生成的散列值均匀随机分布,结果两个内容相似度很高但不完全相同的对象被生成了完全不同的散列值,存放到了完全随机的两个结点上。因此,DHT可以提供精确匹配查询,但是支持语义是非常困难的。
目前在DHT基础上开展带有语义的资源管理技术的研究还非常少。由于DHT的精确关键词映射的特性决定了无法和信息检索等领域的研究成果结合,阻碍了基于DHT的P2P系统的大规模应用。
P2P发现技术中最重要的研究成果应该是基于small world理论的非结构化发现算法和基于DHT的结构化发现算法。尤其是DHT及其发现技术为资源的组织与查找提供了一种新的方法。
随着P2P系统实际应用的发展,物理网络中影响路由的一些因素开始影响P2P发现算法的效率。一方面,实际网络中结点之间体现出较大的差异,即异质性。由于客户机/服务器模式在Internet和分布式领域十几年的应用和大量种类的电子设备的普及,如手提电脑、移动电话或PDA。这些设备在计算能力、存储空间和电池容量上差别很大。另外,实际网络被路由器和交换机分割成不同的自治区域,体现出严密的层次性。
另一方面,网络波动的程度严重影响发现算法的效率。网络波动(Churn、fluctuation of network)包括结点的加入、退出、失败、迁移、并发加入过程、网络分割等。DHT的发现算法如Chord、CAN、Koorde等都是考虑网络波动的最差情况下的设计与实现。由于每个结点的度数尽量保持最小,这样需要响应的成员关系变化的维护可以比较小,从而可以快速恢复网络波动造成的影响。但是每个结点仅有少量路由状态的代价是发现算法的高延时,因为每一次查找需要联系多个结点,在稳定的网络中这种思路是不必要的。
同时,作为一种资源组织与发现技术必然要支持复杂的查询,如关键词、内容查询等。尽管信息检索和数据挖掘领域提供了大量成熟的语义查询技术,由于DHT精确关键词映射的特性阻碍了DHT在复杂查询方面的应用。
P2P普及系列之八
Internet作为当今人类社会信息化的标志,其规模正以指数速度高速增长.如今Internet的“面貌”已与其原型ARPANET大相径庭,依其高度的复杂性,可以将其看作一个由计算机构成的“生态系统”.虽然Internet是人类亲手建造的,但却没有人能说出这个庞然大物看上去到底是个什么样子,运作得如何.Internet拓扑建模研究就是探求在这个看似混乱的网络之中蕴含着哪些还不为我们所知的规律.发现Internet拓扑的内在机制是认识Internet的必然过程,是在更高层次上开发利用Internet的基础.然而,Internet与生俱来的异构性动态性发展的非集中性以及如今庞大的规模都给拓扑建模带来巨大挑战.Internet拓扑建模至今仍然是一个开放性问题,在计算机网络研究中占有重要地位.
Internet拓扑作为Internet这个自组织系统的“骨骼”,与流量协议共同构成模拟Internet的3个组成部分,即在拓扑网络中节点间执行协议,形成流量.Internet拓扑模型是建立Internet系统模型的基础,由此而体现的拓扑建模意义也可以说就是Internet建模的意义,即作为一种工具,人们用其来对Internet进行分析预报决策或控制.Internet模型中的拓扑部分刻画的是Internet在宏观上的特征,反映一种总体趋势,所以其应用也都是在大尺度上展开的.对Internet拓扑模型的需求主要来自以下几个方面1) 许多新应用或实验不适合直接应用于Internet,其中一些具有危害性,如蠕虫病毒在大规模网络上的传播模拟;(2) 对于一些依赖于网络拓扑的协议(如多播协议),在其研发阶段,当前Internet拓扑只能提供一份测试样本,无法对协议进行全面评估,需要提供多个模拟拓扑环境来进行实验;(3) 从国家安全角度考虑,需要在线控制网络行为,如美国国防高级研究计划局(DARPA)的NMS(network modeling and simulation)项目。
随机网络是由N个顶点构成的图中,可以存在条边,我们从中随机连接M条边所构成的网络。还有一种生成随机网络的方法是,给一个概率p,对于中任何一个可能连接,我们都尝试一遍以概率p的连接。如果我们选择M = p,这两种随机网络模型就可以联系起来。对于如此简单的随机网络模型,其几何性质的研究却不是同样的简单。随机网络几何性质的研究是由Paul,Alfréd Rényi和Béla Bollobás在五十年代到六十年代之间完成的。随机网络在Internet的拓扑中占有很重要的位置。
随机网络参数
描述随机网络有一些重要的参数。一个节点所拥有的度是该节点与其他节点相关联的边数,度是描述网络局部特性的基本参数。网络中并不是所有节点都具有相同的度,系统中节点度的分布情况,可以用分布函数描述,度分布函数反映了网络系统的宏观统计特征。理论上利用度分布可以计算出其他表征全局特性参数的量化数值。
聚集系数是描述与第三个节点连接的一对节点被连接的概率。从连接节点的边的意义上,若为第i个节点的度,在由k.个近邻节点构成的子网中,实际存在的边数E(i)与全部k.个节点完全连接时的总边数充的比值定义为节点i的聚集系数。
网管需要买些什么
U盘或移动硬盘,自己认为比较不错的系统盘,光驱DVD刻录的,螺丝刀带磁的,驱动程序兼容比较好的,网线,备用交换机,备用路由器,水晶头,掐线工具,测网线器,正版杀毒软件,条件允许的话最好给你自己弄台电脑.
1、管理信息库浏览器(MIB browsers)
管理信息库(MIB)一个存储网络设备特征的数据库.这些数据库由厂商发布,管理员可以对其中的网络设备的配置和状态信息进行读、写操作.管理信息库浏览器是一种特殊的工具,使用该工具能观察到管理信息库中的数据并提取相关的对象ID(OID)信息.需要注意的是,OID不仅仅是用于表示设备数据唯一地址的一串数字.一个设计良好的管理信息库浏览器应该包含一个预存的已知OID和相关数据的数据库.管理信息库浏览器还具有“走访管理信息库树”的能力,能够收集管理信息库所有的已知数据并将其呈现给管理员.
一个有效的管理信息库浏览器的强大之处在于,它能够观察和搜索管理信息库的相关信息并使得管理员能够根据需要修改和定制这些信息.一个设计良好的管理信息库浏览器一般包含以下功能:
支持远程设备
已知OID的大型数据库
通过树型视图观察/搜索/遍历功能
编辑功能
支持读/写功能
支持多个设备
管理信息库浏览器主要是作为一种定制工具将基于SNMP的设备嵌入到你的网络管理系统中.
2、远程登陆(Telnet)和安全命令行解释(SSH)
Telnet,原本是“TELetype NETwork”的缩写,现在成了一个适合自己的名称,这是一种最常见的将一个系统的命令行控制台会话转发到一个远程主机的机制.Telnet是完全文本式的和命令行驱动的,对新的网络管理员来说,使用起来会有一定的难度.Telnet几乎被所有的UNIX主机和网络设备用于设备配置和管理. SSH或者“安全命令行解释(Secure Shell)”是一种类似的协议,用于实现和Telnet相同的目标,但是具有内在的安全因素.SSH使用公共密钥加密算法来对系统用户进行验证,并为SSH客户端和服务器之间的数据传输提供了机密和完整性机制.由于协议附加的内在安全性,SSH迅速成为了远程终端应用的标准. 对于任何一种协议,Telnet或者SSH客户端软件都是你的故障检修工具箱中必不可少的一种工具.当前存在很多的客户端软件,而且其中一些客户端软件比其它的软件具有更多的特征.当你寻找一个好的Telnet或者SSH客户端软件时,可能需要考虑的一些功能有:
文本色化处理功能
函数密钥映射
远程文件复制支持
服务器连接配置
警报生成功能
脚本记录和重现功能
会话监视功能
安全密码缓存
通常,如果你的网络设备支持,总是优先选择SSH而非Telnet.Telnet以纯文本方式在网络中发送数据和密码,这样就使得网络攻击者可以很容易地“监听”到你的通信.当你通过互联网进行设备连接时,情况尤其如此.
串口工具(Serial port tools)
尽管一个好的Telnet或者SSH客户端软件可以帮助你连接到已经配置好的网络设备,但是在这些设备能够连接到网络之前,通常需要使用板载串口工具对它们进行初始化配置.板载串口工具中包含一个电缆收发器,该收发器将网络设备的串口转换成操作系统可以使用的串口.为了能将操作系统连接到网络设备,就需要一种串口工具.
与Telnet/SSH客户端软件相似,串口工具也是多种多样.例如,HyperTerminal,一种非常基本的串口工具,从微软的Windows 95操作系统开始,一直到现在的Windows Vista操作系统都在使用.然而,由于网络管理员用这些工具进行大量的网络设置和故障检修工作,因此,本地工具的功能还不足以用于进行网络管理.一个好的串口工具应该具有以下功能:
丰富的复制-粘贴功能
支持多终端仿真
打印及打印选择功能
自动化和脚本功能
文本到文件的导出功能
扩展的串口转换支持功能
网络监测工具(Network monitoring)
网络监测工具可能是你的网络管理系统(NMS)中的一个组件或者是一个单独的工具.无论哪种情况,网络监测工具都用于记录和分析网络的特征.网络监测工具能够监测网络性能以及设备资源的使用情况.它们一般将多个网络设备聚集到一个专门的用户接口来进行设备分析.用于故障检修过程的网络监测工具需要具有的一些重要功能有:
多设备监测能力
流量描绘功能
设备资源使用监测功能
通过多种介质进行报警和通知功能
短消息/文本消息功能
SNMP管理功能
流量分析功能
内在流量过滤和聚集功能
3、网络发现工具(Network discovery)
只有当你了解了构成网络的所有设备的时候,才能清楚地知道网络的运行情况.如果问题出现在一台路由器上,不借助于工具你将很难追踪到该设备.网络发现工具就是用来对网络设备进行试探性扫描的.当在一个特定地址发现设备时,网络发现工具记录该位置以及设备类型,并将信息报告给管理员.
目前存在大量的网络发现工具,每一种工具都有其特有的设备查找机制-通过IP地址,MAC地址,SNMP响应,DNS入口,甚至是交换设备上的每个交换端口.网络发现工具一些有用的功能有:
与网络管理系统的结合
多IP范围入口
快速扫描功能
具有SNMP的设备数据库
交换端口映射功能
数据导出到普通文件格式功能
4、攻击识别和仿真工具(Attack identification and simulation)
如果管理员不能了解由于外部攻击引起的网络功能发生变化,那么他将无法在攻击发生时做出反应.攻击识别和仿真工具使得管理员能够在普通的网络攻击(例如,广播风暴、缓存中毒、重放攻击等)发生时对这些攻击进行识别.这些工具还可以对网络上的攻击进行仿真以监测和分析网络的行为,并能够帮助管理员对真实的攻击做好准备.
像网络入侵检测系统和网络入侵保护系统这样的攻击识别工具的安装和管理可能很复杂,因为这些系统往往容易产生一些误导信息.攻击识别和仿真工具具有的一些重要功能有: 性能监测功能
具有实时更新功能的识别数据库
多个攻击配置文件
强制执行能力
网络设备安全检查功能
端口扫描功能
网络阻塞功能
远程TCP重置功能
有所准备的网络管理员都应该拥有攻击仿真工具,因为这些工具能够帮助你成功地维护网络运行.
SNMP捕捉工具(SNMP trapping)
SNMP捕捉接收工具是一系列的工具,能够接收、分析和显示从具有SNMP功能设备上获取的底层捕捉信息,并用于网络管理系统的故障检修和SNMP分析.SNMP捕捉编辑工具使得当捕捉发生时,能够对捕捉模板进行编辑以对网络管理系统响应进行定制.对高级SNMP操作来说,这些工具需要包含以下功能:
将数据导出到普通文件格式的功能
捕捉操作功能
树图显示功能
捕捉模拟和仿真功能
Ping,路由追踪和地址解析协议工具(Ping,Traceroute,and ARP)
尽管ping、路由追踪和地址解析协议命令几乎在所有的操作系统中都存在,但是现在的这些操作系统内的本地工具通常只包含最少的功能.此外,它们一般只能将结果输出到屏幕上,缺乏将本地获得的结果转换成更加常用格式的能力.
对于经常使用这些工具的网络管理员来说,一些附加的功能可能会有助于故障检修过程.下面是一些重要的附加功能:
增强的ping反应时间
将数据导出到普通文件格式的功能
清楚的响应呈现功能
支持多个、同时存在的主机
支持IP地址范围
增强的路由追踪结果信息
远程ping功能
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。